Web scraping with Electron
9 mars 2019 · 4 min read
Web scraping is a technique for extracting content from websites in order to archive data in a structured way. Be careful, however, to respect the terms of use of the website concerned.
Electron is a framework for creating native Windows/Mac/Linux applications with web technologies (Javascript, HTML, CSS). It includes the browser Chromium, fully configurable.
Is there a better way to code a portable application with a graphical user interface to scrape a given site ?
The purpose of this article is not to explain how to develop an application with Electron but to describe the scraping techniques that this framework allows.
At the bottom of this page you will find a link to a GitHub repository with an example of functional source code.
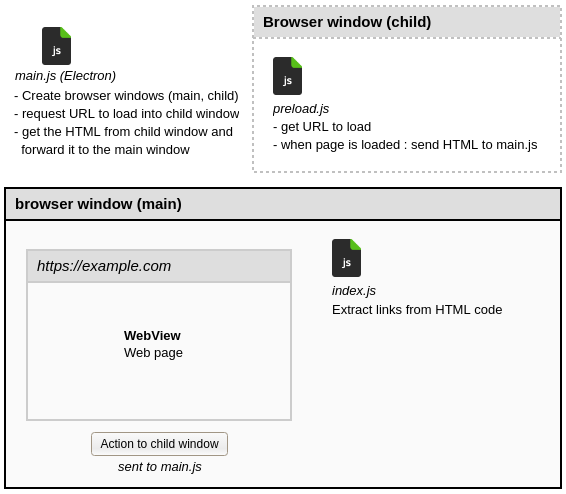
Description of the demonstration application
Navigation in the main window
The main window being intended for the user interface of your application, it is possible to display a web page in a webview. This object allows you to include web content into the current page. For more information, read the Electron documentation about Webview.
<!-- Electron webview -->
<webview
style="min-height: 85vh;"
src="https://www.whatismybrowser.com/detect/what-is-my-user-agent"
useragent="My Super Browser v1.0 Youpi Tralala !">
</webview>
The advantage is that the user-agent can be changed. This text string contains the name of your browser, its version, your operating system and other informations that are transmitted to the web server. You can test your browser on the site WhatIsMyBrowser.com.
In the example above the data concerning your browser is replaced by My Super Browser v1.0 Youpi Tralala !. This allows you to change your “software identity” on the website you are scraping. It is also recommended to change your IP address with a VPN.
Retrieving HTML
We have loaded the page https://www.whatismybrowser.com/detect/what-is-my-user-agent in the webview, how to get its content ? with the following code which is commented for explanations :
// we are manipulating the <webview> component
const webview = document.querySelector('webview')
// when the page is loaded
webview.addEventListener('dom-ready', () => {
// we can get its URL and display it in the console
let currentURL = webview.getURL()
console.log('currentURL is : ' + currentURL)
// same thing about the title of the page
let titlePage = webview.getTitle()
console.log('titlePage is : ' + titlePage)
// executing Javascript into the webview to get the full HTML
webview.executeJavaScript(`function gethtml () {
return new Promise((resolve, reject) => { resolve(document.documentElement.innerHTML); });
}
gethtml();`).then((html) => {
// sending the HTML to the function extractLinks
extractLinks(html)
})
})
Extracting links
To navigate in the HTML elements, we can use Cheerio which is to Javascript what BeautifulSoup is to Python. Here is an example to extract the internet links contained in a page :
let extractLinks = function (html) {
// loading the HTML code
const $ = cheerio.load(html)
// for each link <a href=...></a>
$('a').each((i, element) => {
// printing the "href" attribute and the link text
console.log('href: ' + $(element).attr('href'))
console.log('text: ' + $(element).text())
})
}
Navigation in a child window
Electron can open other browser windows. This allows, for example, to delegate loading and extraction processing to a hidden window. To do this, simply use the show: false parameter when creating it.
Example of creating a hidden window dedicated to loading web pages:
let childWindow = new BrowserWindow({
parent: mainWindow,
center: true,
minWidth: 800,
minHeight: 600,
show: true,
webPreferences: {
nodeIntegration: false,
preload: path.join(__dirname, 'app/js/preload.js')
}
})
childWindow.webContents.on('dom-ready', function () {
console.log('childWindow DOM-READY => send back html')
childWindow.send('sendbackhtml')
})
The nodeIntegration: false option is used for security reasons related to the display of remote content. Read the Electron documentation for more information about this.
The script app/js/preload.js is injected into the child window. It will allow communication with the main program : in our case, to send the HTML code of the loaded page.
Each time a page is ready in the child window (dom-ready event), the code childWindow.send('sendbackhtml') asks it to respond to the sendbackhtml event.
Here is the code of the file app/js/preload.js that responds to this event:
const { ipcRenderer } = require('electron')
ipcRenderer.on('sendbackhtml', (event, arg) => {
console.log('preload: received sendbackhtml')
ipcRenderer.send('hereishtml', document.documentElement.innerHTML)
})
The HTML code is transmitted to the main program main.js which can send it back to the main window for link extraction :
ipcMain.on('hereishtml', (event, html) => {
mainWindow.send('extracthtml', html)
})
Demonstration
A functional application is available if you want to go further and perform some tests : Sample Web Scraping With Electron. Here is a screenshot:
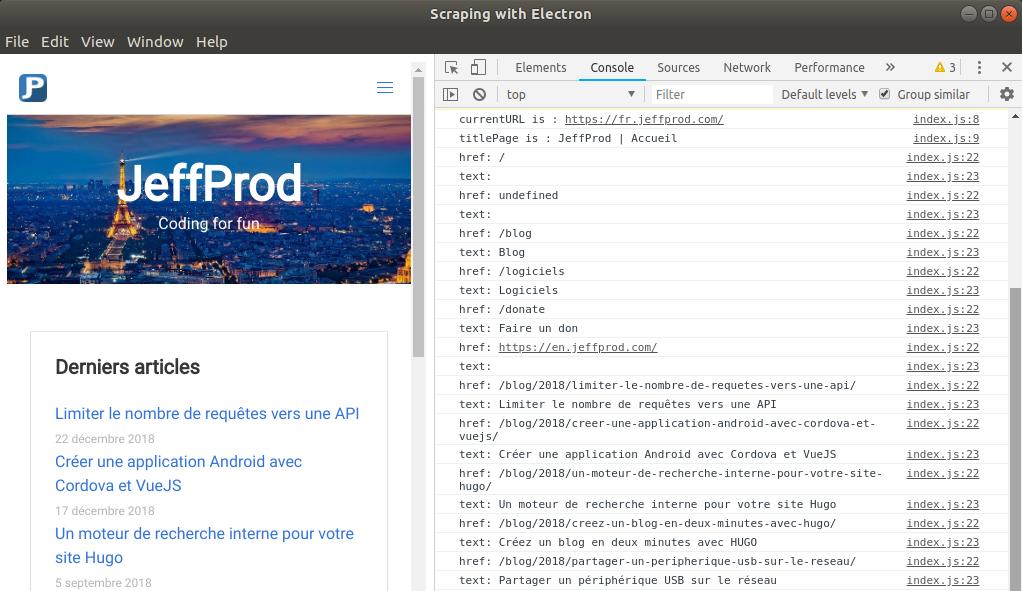 Loading the jeffprod.com website and listing all links contained in the page.
Loading the jeffprod.com website and listing all links contained in the page.
Conclusion
You now have all informations to code a scraping application with a graphical user interface. Navigation can be manual or automated. The pages can be loaded in a child window or in a webview. In any case, HTML can be retrieved and transmitted between components for processing.
Références
- Cheerio
- Webwiew Electron
- Example GiHtub project : Sample Web Scraping With Electron